Why Another Storage Array?
The cost of storage is dominating the cost of the competitive business process and this MUST change. Learn what Infinidat is doing to help provide clients with ‘no compromise’ storage to get the most performance, highest reliability and largest scale at disruptive price points. Transcript below:
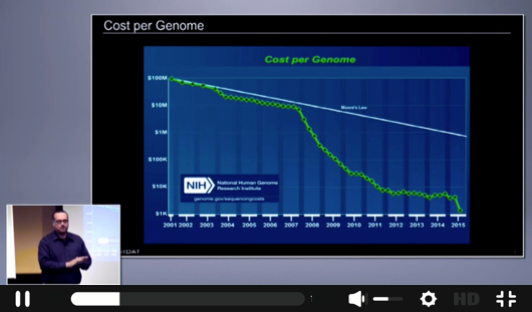
[Brian Carmody] I'd actually like to start with a "why" question, which is, why do this at all? Why another storage company? This is why. So you guys probably know at the beginning of the last decade, we sequenced the first complete human genome. It was called the Human Genome Project. It was a pretty big deal. And that first genome -- that first 2 billion-odd base pairs cost $100 million to sequence. And since then, the cost has dropped by five orders of magnitude.
So forget about Moore's law and Kryder's law and all the things that we're proud of as technologists. The biologists are kicking our ass. And this is actually a very serious problem. We are at the point now where the TCO of a sequenced human genome is dominated by the cost of storing the bits and bytes all the way at the end of the pipeline. Genomics has become a data storage problem. And why do we care?
So there are conversations going on right now between genomics companies and nation states to sequence the genome of every citizen. And this will become the first record in the child's electronic medical health record, and it will form the basis of what's called personalized medicine. This is going to fundamentally transform medicine like we have never seen in our lifetime. This is going to be up there with the germ theory of disease and the polio vaccine. It's within reach. It's happening right now, but we have a huge data storage problem.
We are talking about hundreds of exabytes of data at scale. It is safety and life critical data. A bit flip, in this case, is the digital equivalent of a mutation. It's misidentification of a tumor. It's giving the wrong medicine to a patient. It has to be cheap enough that not only first world countries, but emerging economies too can afford to do this for their citizens. And this data has to be stored and organized in such a way that it's easy to compute on.
We can't do this with tape. It has to be super high performance. It has to be online. There is no technology that exists that makes this possible yet. The reason why I told this story is that a couple of years ago, a computational biologist explained this to my boss. He told him that the biggest problem that he has in his lab has nothing to do with biology -- it's what to do with these petabytes of data that are coming out of the sequencing machines -- how to analyze them, how to store them.
The scientific mission was being held back by IT. And anyway, contemplation of this question brought together a group of storage engineers who developed a kernel of an idea of software architecture that can solve this. And I'm here to give you an update on where we're at five years later -- a couple of million lines of C++, Python, and Java, over a person's century of software development time, and $230 million worth of capital later.